Generating mixtures with Scaper¶
In this section we will learn how to generate training data for music source separation using the Scaper python library. Parts of this section are based on the Scaper tutorial.
Why Scaper?¶
Before we dive in, you might be wondering why we need a Python library to mix stems at all - can’t we just sum them in Python? What about data loaders provided by deep learning frameworks such as PyTorch and TensorFlow - can’t we just use those?
While there are various ways to programatically generate mixes, we will see that Scaper is particularly well suited for this task, offering a number of benefits that make it much preferable to simple mixing via ad-hoc code:
Scaper supports complex, programatic, and stochastic mixing pipelines:
For example, it can sample mixing parameters (such as per-stem SNR and augmentation parameters) from a variety of distributions. This allows you to generate a potentially infinite number of unique mixtures from the same set of stems.
Scaper supports data augmentation and normalization
Scaper includes data augmentation operations such as pitch shifting and time-stretching. It also provides easy-to-use options such as
fix_clippingso that no matter how many stems you mix together or what SNR values you use, you can be sure your audio does not distort.
Scaper pipelines are reproducible
Scaper generates detailed annotation files - you can re-create an entire dataset of mixtures just from Scaper’s annotations as long as you have access to the stems. Furthermore, Scaper code can be initialized with a random seed, such that code run with the same seed always generates the same sequence of randomized mixtures. This allows you to share your scaper code + stems as a “recipe” for generating data: there’s no need to the actual (heavy) mixtures!
Scaper is optimized for performance
Scaper can generate training data on the fly for GPU training without being a bottleneck. It’s also good for batch generation, for example, on a machine with 8 CPUs, Scaper can generate 20,000 ten-second mixtures (mix + stems + annotations) in under 10 minutes.
Scaper can generate data for other audio domains
Scaper can generate speech/noise mixtures for training Automatic Speech Recognition (ASR), environmental soundscapes for sound event detection (SED) and classification (SEC), bioacoustic mixtures for species classification, etc. Once you know how to use Scaper for one audio domain, you know how to use it for all audio domains.
Scaper is documented, tested, actively maintained and updated
Will your ad-hoc mixing code work a few years from now? Will you remember how to use it? Will someone else know how to use it? Does it cover all corner cases? Can it be easily extended to support new features? Ad-hoc mixing code might seem like a time saver in the short term, but it’s bound to be a time sink in the long run.
Scaper overview¶
Scaper can be viewed as a programatic audio mixer. At a high-level, the input to Scaper is:
source material: audio recordings you want to mix together (“soundbank” in the diagram below).
event specification: a “recipe” for how to mix the recordings.
Scaper takes these and generates mixtures using the source material by following the event specification. Since the event specification can be probabilistic, multiple different mixtures can be generated from the same source material and event specification. For each generated mixture Scaper outputs:
The mixture audio signal (“soundscape” in the diagram).
The mixture annotation in JAMS format (detailed) and in a simpligied tabular format (python list or csv).
The audio of each processed stem (or sound event) used to create the mixture.
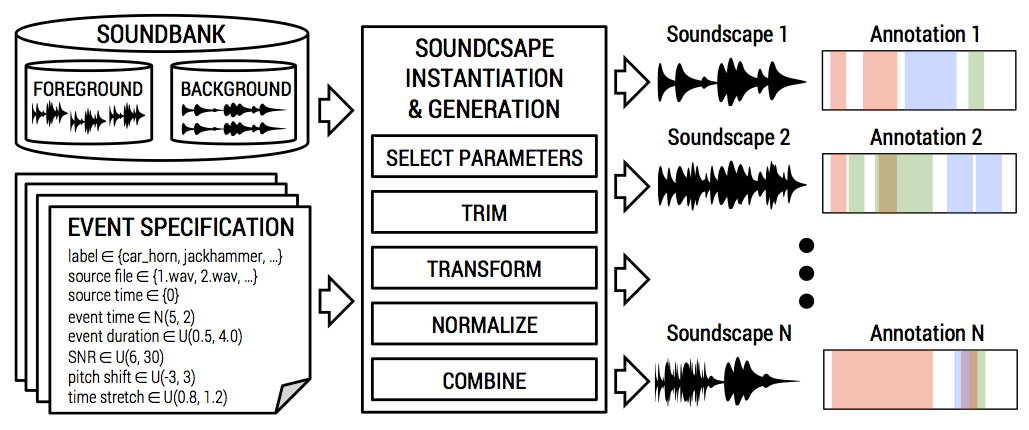
Fig. 47 Block diagram of automatic mixing via Scaper.¶
Read more¶
You can learn more about Scaper by reading the scaper-paper: Scaper: A library for soundscape synthesis and augmentation
@inproceedings{Salamon:Scaper:WASPAA:17,
author = {Salamon, J. and MacConnell, D. and Cartwright, M. and Li, P. and Bello, J.~P.},
title = {Scaper: A Library for Soundscape Synthesis and Augmentation},
booktitle. = {IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
month = {Oct.},
year = {2017},
pages = {344--348}
}
Please cite this paper if you use Scaper in your work. You do not need to read the paper to complete this tutorial.
Installing Scaper, nussl, and other dependencies¶
We can easily install Scaper and nussl via:
pip install scaperpip install nussl
We’ll also install the common utility library we have created for this tutorial so we can easily visualize our data:
%%capture
!pip install scaper
!pip install nussl
!pip install git+https://github.com/source-separation/tutorial
To keep the tutorial page clean, we’ll hide Python warnings:
# To keep things clean we'll hide all warnings
import warnings
warnings.filterwarnings('ignore')
Preparing the source material¶
Download MUSDB18 training clips¶
We’ll use the stems of the MUSDB18 dataset as our source material. Let’s start by downloading the data - as explained in The MUSDB18 dataset we’ll be using 7-second preview clips of the dataset rather than the full dataset.
As we did earlier, let’s download the train set data via nussl:
(don’t worry if you get a warning from SoX, everything will still work as expected)
import nussl
musdb_train = nussl.datasets.MUSDB18(download=True, subsets=['train'])
# Confirm there are 94 training clips
len(musdb_train.items)
94
Prepare the source material for Scaper¶
Scaper expects the source material to be grouped into two categories: foreground files and background files. When Scaper is used to generate soundscapes (e.g., for sound event detection), this distinction is used to separate material used for background tracks and material used for foreground sound events (for further details about this distinction see this section of the Scaper tutorial).
Since we’ll be using Scaper to generate music mixtures, however, we do not require this foreground/background distinction and so we will place all of our stems in the foreground folder.
For music source separation, Scaper expects the following file structure:
foreground/
|--- drums/
|--- stem.wav
|--- bass/
|--- stem.wav
|--- vocals/
|--- stem.wav
|--- other/
|--- stem.wav
background/
(empty)
That is, inside the foreground folder there should be a folder per stem type (drums, bass, vocals, other), and within each stem (label) folder we store the audio file for the corresponding stem.
Note
Generally in Scaper the name of the stem file does not matter as long as its an audio file with a .wav extension. For music source separation, however, it is helpful to choose a meaningful filename that we can use to link stems from the same song. A good convention (that we will use) is to give all stems from the same song the same filename (remember the stems go in different folders), for example song_name.wav.
To make this step easy and quick, we have provided code below to arrange the MUSDB18 training clips in the folder structure expected by Scaper. This code will:
Iterate over each item (track) in the train set
For each track, iterate over its sources (stems)
For each stem, create a folder for the stem if one doesn’t exist already (
drums,bass,vocals,other)For each stem, place the corresponding audio file in the stem folder and use the song name as the filename
from pathlib import Path
# create foreground folder
fg_folder = Path('~/.nussl/ismir2020-tutorial/foreground').expanduser()
fg_folder.mkdir(parents=True, exist_ok=True)
# create background folder - we need to provide one even if we don't use it
bg_folder = Path('~/.nussl/ismir2020-tutorial/background').expanduser()
bg_folder.mkdir(parents=True, exist_ok=True)
# For each item (track) in the train set, iterate over its sources (stems),
# create a folder for the stem if it doesn't exist already (drums, bass, vocals, other)
# and place the stem audio file in this folder, using the song name as the filename
for item in musdb_train:
song_name = item['mix'].file_name
for key, val in item['sources'].items():
src_path = fg_folder / key
src_path.mkdir(exist_ok=True)
src_path = str(src_path / song_name) + '.wav'
val.write_audio_to_file(src_path)
Now we have a folder called foreground, inside of which there are four stem folders: bass, drums, vocals, other, and inside each of these folders we have the audio files for all matching stems. I.e., in the bass folder we will have the bass stems from all the songs in the dataset, in the drums folder we’ll have the drum stems from all songs, etc. We’ve renamed each stem file to the name of the song it belongs to. Let’s verify this:
import os
import glob
for folder in os.listdir(fg_folder):
if folder[0] != '.': # ignore system folders
stem_files = os.listdir(os.path.join(fg_folder, folder))
print(f"\n{folder}\tfolder contains {len(stem_files)} audio files:\n")
for sf in sorted(stem_files)[:5]:
print(f"\t\t{sf}")
print("\t\t...")
drums folder contains 94 audio files:
A Classic Education - NightOwl.wav
ANiMAL - Clinic A.wav
ANiMAL - Easy Tiger.wav
ANiMAL - Rockshow.wav
Actions - Devil's Words.wav
...
vocals folder contains 94 audio files:
A Classic Education - NightOwl.wav
ANiMAL - Clinic A.wav
ANiMAL - Easy Tiger.wav
ANiMAL - Rockshow.wav
Actions - Devil's Words.wav
...
other folder contains 94 audio files:
A Classic Education - NightOwl.wav
ANiMAL - Clinic A.wav
ANiMAL - Easy Tiger.wav
ANiMAL - Rockshow.wav
Actions - Devil's Words.wav
...
bass folder contains 94 audio files:
A Classic Education - NightOwl.wav
ANiMAL - Clinic A.wav
ANiMAL - Easy Tiger.wav
ANiMAL - Rockshow.wav
Actions - Devil's Words.wav
...
Note
The name of each stem audio file matches the name of the song to which it belongs. We will use this later to create “coherent mixtures”, i.e., music mixtures where all the stems come from the same song and are temporally aligned.
Defining a Scaper object¶
After organizing our source material, the next step is to create a Scaper object.
Upon creating the object, we will define:
duration: the duration in seconds of the mixtures this Scaper will generate (fixed once defined)fg_path,bg_path: the paths to the foreground and background folders with the source material we have prepared and organizedrandom_state: a seed for initializing this Scaper object’s random state.
Let’s create a Scaper that generates 5-second mixtures:
import scaper
seed = 123 # integer or np.random.RandomState(<integer>)
sc = scaper.Scaper(
duration=5.0,
fg_path=str(fg_folder),
bg_path=str(bg_folder),
random_state=seed
)
Note
We will use this Scaper to generate a randomized sequence of mixtures. By seeding the Scaper object’s random state, this sequence will be exactly the same each time we run our code. This guarantees that our data generation pipeline is fully reproducible (by others and by ourselves). Changing the seed will result in a different sequence of random mixtures.
Next let’s set some key parameters:
sr: the sample rate for the output audion_channels: the number of channels for the output audio (1 = mono)ref_db: a reference loudness in decibels (dB) for generating the mixture.
sc.sr = 44100
sc.n_channels = 1
sc.ref_db = -20
Note
When we add stems to the mixture later on, we will choose a Signal-to-Noise Ratio (SNR) in dB relative to the reference loudness ref_db. For example, if ref_db is -20, and we mix a stem with an SNR value of 10, then it will have a dB value of -10. A high ref_db value will produce loud mixtures, and a low value will produce soft mixtures.
Note
All absolute loudness values in Scaper are measured in LUFS (Loudness units relative to full scale) - a standard loudness measurement unit used for audio normalization in broadcast television systems and other video and music streaming services. For relative loudness, a difference of 1 LUFS is equal to 1 dB. For convenience, we’ll use dB to refer both to absolute and relative loudness in this section.
Adding events (stems)¶
Next we need to add stems to our mixture. In Scaper we do this by adding “events”, using the add_event function.
For each event that we add we specify the following:
label: the type of event (in our casedrums,bass,vocalsorother)source_file: which audio file to use from all files matching the provided labelsource_time: time offset for sampling the stem audio file, i.e., where to start in the source audioevent_time: offset for the start time of the event in the generated mixtureevent_duration: how long the event should last in the mixturesnr: the event’s signal-to-noise ratio relative toref_dbpitch_shift: whether to apply a pitch shifting augmentation to the event and if so by how muchtime_stretch: whether to apply a time stretching augmentation to the event and if so by how much
Probabilistic event parameters¶
If we set each event parameter to a constant value (which we could in principle), the Scaper object would always generate the same mixture, which isn’t very helpful. Instead, for each parameter we can specify a distribution to sample from, such that each time we call sc.generate(...) later on, the value of the parameter will be different.
By setting event parameters to distributions, we obtain a probabilistic event specification. When we call sc.generate(...), a mixture will be “instantiated” by sampling a value for every parameter from the distribution we have specified for it.
In Scaper, distributions are defined using “distribution tuples”:
('const', value): a constant, given byvalue.('choose', list): uniformly sample from a finite set of values given bylist.('uniform', min, max): sample from a uniform distribution betweenminandmax.('normal', mean, std): sample from a normal distribution with meanmeanand standard deviationstd.('truncnorm', mean, std, min, max): sample from a truncated normal distribution with meanmeanand standard deviationstd, limited to values betweenminandmax.
This is one of Scaper’s key features - the ability to add stochastic (i.e., randomized) events. The same event specification can generate infinitely many different mixtures, because the event parameters are sampled from distributions.
Let’s add one event per stem type in a loop:
labels = ['vocals', 'drums', 'bass', 'other']
for label in labels:
sc.add_event(label=('const', label), # set the label value explicitly using a constant
source_file=('choose', []), # choose the source file randomly from all files in the folder
source_time=('uniform', 0, 7), # sample the source (stem) audio starting at a time between 0-7
event_time=('const', 0), # always add the stem at time 0 in the mixture
event_duration=('const', sc.duration), # set the stem duration to match the mixture duration
snr=('uniform', -5, 5), # choose an SNR for the stem uniformly between -5 and 5 dB
pitch_shift=('uniform', -2, 2), # apply a random pitch shift between -2 and 2 semitones
time_stretch=('uniform', 0.8, 1.2)) # apply a random time stretch between 0.8 (faster) and 1.2 (slower)
Tip
It is very important to choose sensible ranges for your parameter distributions. In the example above we have set the snr range to [-5, 5], meaning sources will be at most 10 db louder than each other. Similarity, we have limited the range of pitch shifts to [-2, 2] semitones. Extreme parameter values can to lead to unrealistic mixtures.
Generating data¶
Now that we have added events to our Scaper object, we can call sc.generate(): this will “instatiate” (sample concrete values from) the specification and use them to generate a mixture. Each call to sc.generate() will create different instatiation of the events’ parameters and thus generate a different mixture.
mixture_audio, mixture_jam, annotation_list, stem_audio_list = sc.generate()
Note
When we call generate(), Scaper will raise warnings if the sampled event parameters cannot be satisfied (e.g. we request an event_duration of 100 seconds but the source_file is only 10 seconds long), and let us know how it adjusted the values so that they can be satisfied. To keep things clean we have disabled these warnings in this section. Once you copmlete this section you may want re-run this notebook without disabling warnings to examine the warnings that Scaper issues.
Let’s understand the output from generate():
mixture_audio: the audio data of the generated mixture in numpy ndarray formatmixture_jam: the mixture annotation, in JAMS formatannotation_list: a simplified mixture annotation in list format (we will not use this)stem_audio_list: a python list containing the audio of the individual stems (events) in the mixture
Let’s inspect the JAMS annotation, where we can find the values Scaper has sampled for the parameters of the four events we have added. The complete set of parameters is specified in the “value” field of the annotated event.
# extract the annotation data from the JAMS object
ann = mixture_jam.annotations.search(namespace='scaper')[0]
# print the sampled parameters for each event in the annotation
for event in ann:
print(f"\n{event.value['label']}:\n")
print(event.value)
vocals:
OrderedDict([('label', 'vocals'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/vocals/Port St Willow - Stay Even.wav'), ('source_time', 0.9942668075895806), ('event_time', 0), ('event_duration', 5.0), ('snr', 2.1946896978556305), ('role', 'foreground'), ('pitch_shift', -0.30757415950215616), ('time_stretch', 0.8907405814256812)])
drums:
OrderedDict([('label', 'drums'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/drums/Traffic Experiment - Sirens.wav'), ('source_time', 1.0454477739410935), ('event_time', 0), ('event_duration', 5.0), ('snr', -3.600492373696155), ('role', 'foreground'), ('pitch_shift', -0.39592977335518587), ('time_stretch', 0.9643697490836076)])
bass:
OrderedDict([('label', 'bass'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/bass/Dreamers Of The Ghetto - Heavy Love.wav'), ('source_time', 0.10762590642068458), ('event_time', 0), ('event_duration', 5.0), ('snr', -1.0195574466956856), ('role', 'foreground'), ('pitch_shift', 0.9519816229281428), ('time_stretch', 0.9754288978718497)])
other:
OrderedDict([('label', 'other'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/other/Music Delta - Beatles.wav'), ('source_time', 0.15099625329503377), ('event_time', 0), ('event_duration', 5.0), ('snr', 2.1233018138876245), ('role', 'foreground'), ('pitch_shift', -0.288546036648722), ('time_stretch', 0.9761028712256306)])
Note
In Jupyter notebooks, JAMS annotations can be visualized interactively, but this cannot be displayed in the static book format. We encourage you to run this section as a jupyter notebook to explore the annotation data interactively.
# Launch this cell in a Jupyter notebook to generate an interactive vizualization of the annotation!
ann
| time | duration | value | confidence | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000 | 4.454 |
|
1.0 | ||||||||||||||||||
| 1 | 0.000 | 4.822 |
|
1.0 | ||||||||||||||||||
| 2 | 0.000 | 4.877 |
|
1.0 | ||||||||||||||||||
| 3 | 0.000 | 4.881 |
|
1.0 |
sc.generate() provides a large set of configuration parameters that impact the generated audio. In this tutorial we’ll discuss two important parameters:
fix_clipping: whenTrue, ensures the mixture does not clip by peak normalizing the mixture and adjusting the loudness of its constituent stems accordingly.quick_pitch_time: whenTrue, uses faster but lower-quality algorithms for pitch shifting and time stretching, which can dramatically speed up data generation. In this section we’ll leave this parameter set toFalse, but later in this tutorial we will use it to maximize training speed.
Tip
It is important to set fix_clipping=True in when calling sc.generate(), otherwise our mixtures can distort.
Let’s generate another mixture using the same Scaper object:
mixture_audio, mixture_jam, annotation_list, stem_audio_list = sc.generate(fix_clipping=True)
We can inspect the annotation to see the sampled mixture parameters are all different:
ann = mixture_jam.annotations.search(namespace='scaper')[0]
for event in ann:
print(f"\n{event.value['label']}:\n")
print(event.value)
vocals:
OrderedDict([('label', 'vocals'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/vocals/Night Panther - Fire.wav'), ('source_time', 1.7507239493214413), ('event_time', 0), ('event_duration', 4.386839518664663), ('snr', 1.1102351067758285), ('role', 'foreground'), ('pitch_shift', 0.8897735302808862), ('time_stretch', 1.1397727176311159)])
drums:
OrderedDict([('label', 'drums'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/drums/Traffic Experiment - Once More (With Feeling).wav'), ('source_time', 0.4116605732032902), ('event_time', 0), ('event_duration', 5.0), ('snr', -2.0628595361117066), ('role', 'foreground'), ('pitch_shift', 0.523904495417951), ('time_stretch', 0.9447154622489257)])
bass:
OrderedDict([('label', 'bass'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/bass/Skelpolu - Human Mistakes.wav'), ('source_time', 0.7770380338578964), ('event_time', 0), ('event_duration', 5.0), ('snr', -0.06314902349693785), ('role', 'foreground'), ('pitch_shift', -0.2966788388166881), ('time_stretch', 0.9734804690718113)])
other:
OrderedDict([('label', 'other'), ('source_file', '/home/runner/.nussl/ismir2020-tutorial/foreground/other/Bill Chudziak - Children Of No-one.wav'), ('source_time', 1.611179748776235), ('event_time', 0), ('event_duration', 5.0), ('snr', 4.441600182038796), ('role', 'foreground'), ('pitch_shift', 0.007346703537346233), ('time_stretch', 0.9705405227851233)])
# Launch this cell in a Jupyter notebook to generate an interactive vizualization of the annotation!
ann
| time | duration | value | confidence | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000 | 5.000 |
|
1.0 | ||||||||||||||||||
| 1 | 0.000 | 4.724 |
|
1.0 | ||||||||||||||||||
| 2 | 0.000 | 4.867 |
|
1.0 | ||||||||||||||||||
| 3 | 0.000 | 4.853 |
|
1.0 |
Incoherent mixing¶
So far we’ve only inspected the annotation… let’s listen to our generated audio!
from IPython.display import Audio, display
display(Audio(data=mixture_audio.T, rate=sc.sr))
…Wait! WHAT WAS THAT? CHAOS! CACOPHONY!
That’s because we just generated an incoherent mixture, i.e., a mixture where the stems are not necessarily from the same song, and even if they are, they are not necessarily temporally aligned:
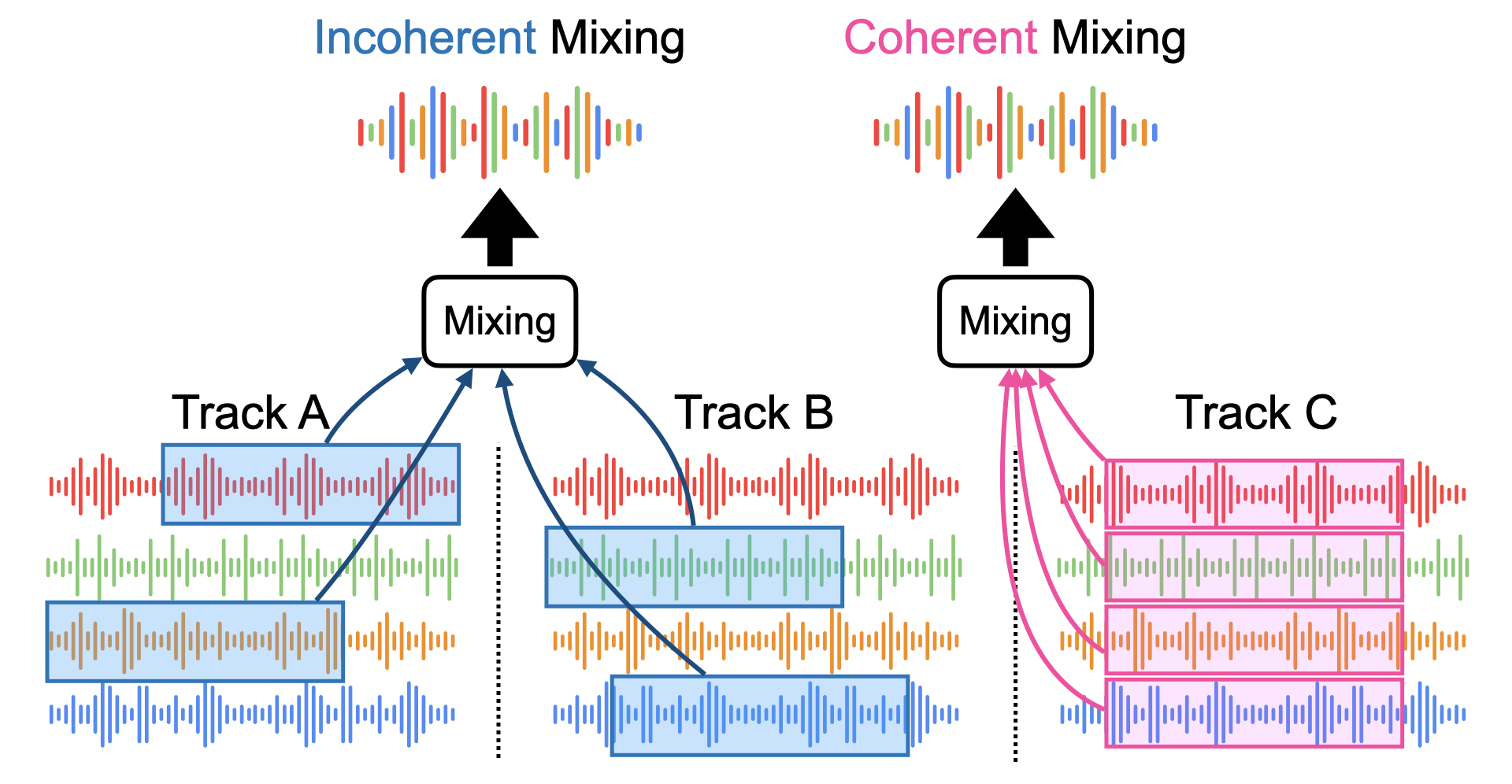
Fig. 48 Incoherent mixing vs coherent mixing.¶
We can verify this by listening to the individual stems:
# extract the annotation data from the JAMS object
ann = mixture_jam.annotations.search(namespace='scaper')[0]
# iterate over the annotation and corresponding stem audio data
for obs, stem_audio in zip(ann.data, stem_audio_list):
print(f"Instrument: {obs.value['label']} at SNR: {obs.value['snr']:.2f}")
display(Audio(data=stem_audio.T, rate=sc.sr))
Instrument: vocals at SNR: 1.11
Instrument: drums at SNR: -2.06
Instrument: bass at SNR: -0.06
Instrument: other at SNR: 4.44
These stems clearly did not all come from the same song.
When do we want incoherent mixing?¶
Incoherent mixing is clearly not representative of real-world recorded music. So why do we want to mix together stems in this way? It turns out, incoherent mixing is an important data augmentation technique when we train a one-vs-all (OVA) source separation network.
A one-vs-all (OVA) source separation model is trained to only separate one source from the mixture and ignore all other sources. In contrast to OVA systems, multisource networks are trained to separate and output multiple sources simultaneously.
When we train an OVA network with incoherent mixing, we’re teaching the network to “ignore everything you hear except my source”.
To separte more than one source using the OVA approach, we need multiple networks - one per source. The trade-off with respect to multisource networks is that each OVA network learns from a more diverse pool of data, but we need to train multiple OVA networks.
Tip
Training multiple one-vs-all (OVA) source separation networks is a popular paragidm that is frequently encoutered in research papers. Under this setup, incoherent mixing can be used as a data augmentation technique to acheive to better performance.
When Do we not want incohereht mixing?¶
In theory, we could use incoherent mixtures to train any music source separation model, but:
Music is (usually) coherent - people play together and the stems are aligned in time.
Coherent sources are harder to separate: there is a great degree of overlap in harmonic and percussive content
If we want to separate multiple sources at once using a multisource network, we need coherent mixtures. When coupled with incoherent mixtures, coherent mixtures can also make OVA models more robust. Let’s see how to generate coherent mixtures with Scaper.
Coherent mixing¶
To generate cohernet mixtures (cf. Incoherent mixing vs coherent mixing.), we need to ensure that:
All stem source files belong to the same song
We use the same time offset for sampling all source files (i.e., same
source_time)
Let’s see how this is done. The following code will:
Define a random seed
Create a Scaper object
Set the sample rate, reference dB, and channels (mono)
Define a template of probabilistic event parameters
Add the template event and instantiate it (=sample concrete values) to randomly choose a song
source_file, a start time for the sourcessource_time, apitch_shiftvalue and atime_stretchvalue.Reset the Scaper’s event specficiation
Replace the distributions for source time, pitch shift and time stretch in the template with the constant values we just sampled
Iterate over the four stems (
vocals,drums,bass,other) and add COHERENT stems.By keeping the
source_filepath fixed except for changing the parent folder (voice,drums,bass, orother) we ensure all stems in the mixture come from the same song. This is critical for achieving a COHERENT mix.
Note
To ensure coherent source files (all from the same song) in step 8, we leverage the fact that all the stems from the same song have the same filename. All we have to do is replace the sampled source file’s parent folder name to the label of the stem being added in each iteration of the loop (voice, drums, bass, or other), which will give the correct path to the stem source file for that label.
# 1. Define a random seed
random_state = 123
# 2. Create a Scaper object
sc = scaper.Scaper(
duration=5.0,
fg_path=str(fg_folder),
bg_path=str(bg_folder),
random_state=random_state
)
# 3. Set sample rate, reference dB, and channels (mono)
sc.sr = 44100
sc.ref_db = -20
sc.n_channels = 1
# 4. Define a template of probabilistic event parameters
event_parameters = {
'label': ('const', 'vocals'),
'source_file': ('choose', []),
'source_time': ('uniform', 0, 7),
'event_time': ('const', 0),
'event_duration': ('const', sc.duration),
'snr': ('uniform', -5, 5),
'pitch_shift': ('uniform', -2, 2),
'time_stretch': ('uniform', 0.8, 1.2)
}
# 5. Instatiate the template once to randomly choose a song,
# a start time for the sources, a pitch shift and a time
# stretch. These values must remain COHERENT across all stems
# Add a an event based on the probabilistic template
sc.add_event(**event_parameters)
# Instantiate the event to sample concrete values
event = sc._instantiate_event(sc.fg_spec[0])
# 6. Reset the Scaper object's event specficiation
sc.reset_fg_event_spec()
# 7. Replace the distributions for source time, pitch shift and
# time stretch with the constant values we just sampled, to
# ensure our added events (stems) are coherent.
# NOTE: the source_file has also been sampled, and we'll keep
# the sampled file to denote which song we'll be mixing.
event_parameters['source_time'] = ('const', event.source_time)
event_parameters['pitch_shift'] = ('const', event.pitch_shift)
event_parameters['time_stretch'] = ('const', event.time_stretch)
# 8. Iterate over the four stems (vocals, drums, bass, other) and
# add COHERENT events.
labels = ['vocals', 'drums', 'bass', 'other']
for label in labels:
# Set the label to the stem we are adding
event_parameters['label'] = ('const', label)
# To ensure coherent source files (all from the same song), we leverage
# the fact that all the stems from the same song have the same filename.
# All we have to do is replace the stem file's parent folder name from "vocals"
# to the label we are adding in this iteration of the loop, which will give the
# correct path to the stem source file for this current label.
coherent_source_file = event.source_file.replace('vocals', label)
event_parameters['source_file'] = ('const', coherent_source_file)
# Add the event using the modified, COHERENT, event parameters
sc.add_event(**event_parameters)
Now each time we call generate we’ll get a coherent mixtrue. Since we’ve fixed the song and source_time (and augmentation parameters), we’ll always get a mixture for the same 5 seconds of the same song, but the SNR values will be different each time. For convenience we’ll wrap our code in a function so we can easily call it multiple times:
def generate_and_play(sc):
mixture_audio, mixture_jam, annotation_list, stem_audio_list = sc.generate(fix_clipping=True)
print("Mixture:")
display(Audio(data=mixture_audio.T, rate=sc.sr))
# extract the annotation data from the JAMS object
ann = mixture_jam.annotations.search(namespace='scaper')[0]
# iterate over the annotation and corresponding stem audio data
for obs, stem_audio in zip(ann.data, stem_audio_list):
print(f"Instrument: {obs.value['label']} at SNR: {obs.value['snr']:.2f}")
display(Audio(data=stem_audio.T, rate=sc.sr))
generate_and_play(sc)
Mixture:
Instrument: vocals at SNR: 4.81
Instrument: drums at SNR: 1.85
Instrument: bass at SNR: -0.19
Instrument: other at SNR: -1.08
generate_and_play(sc)
Mixture:
Instrument: vocals at SNR: -1.57
Instrument: drums at SNR: 2.29
Instrument: bass at SNR: -0.61
Instrument: other at SNR: -4.40
generate_and_play(sc)
Mixture:
Instrument: vocals at SNR: -1.02
Instrument: drums at SNR: 2.38
Instrument: bass at SNR: -3.18
Instrument: other at SNR: -3.25
Putting it all together¶
Now that we know how to generate coherent and incoheret mixtures, let’s create functions for both types so we can easily generate them inside our training pipelines.
Note
There are two ways to use seeds with Scaper when looping to generate multiple mixtures:
Create one Scaper object outside the loop, seed it once outside the loop, and call
sc.generate()inside the loop.Create the Scaper object inside the loop using a different seed each time (e.g., 0, 1, 2, …) and call
sc.generate()inside the loop.
Both options will generate a sequence of random mixtures, but there’s an important difference:
In Option 1 we use one random seed to initiate one sequence, and sample from this sequence at each iteration of the loop.
In Option 2 we initiate a new sequence with a different seed in each iteration of the loop, and sample just one mixture from this new sequence.
Both approaches are reproducible, but will generate different seqeunces of random mixtures. For our use case, Option 2 has some advantages:
We can generate a specific mixture from the radnom sequence without having to re-genreate all mixtures up to the one we want. This can be very helpful when we are generating training data on-the-fly and subsequently want to re-generate a specific sample that was used during training.
For batch generation, we can parallelize generation across machines by dividing the sequence of seeds we use into subsets and using a different subset per machine (e.g. machine 1 uses seed 0-4999, and machine 2 uses seeds 5000-9999).
In the code below we’ll use Option 2, i.e., we’ll define our functions to take a seed as input, and it will be our responsibility to call the functions with a different seed each time to get a different mixture:
# Create a template of probabilistic event parameters
template_event_parameters = {
'label': ('const', 'vocals'),
'source_file': ('choose', []),
'source_time': ('uniform', 0, 7),
'event_time': ('const', 0),
'event_duration': ('const', 5.0),
'snr': ('uniform', -5, 5),
'pitch_shift': ('uniform', -2, 2),
'time_stretch': ('uniform', 0.8, 1.2)
}
def incoherent(fg_folder, bg_folder, event_template, seed):
"""
This function takes the paths to the MUSDB18 source materials, an event template,
and a random seed, and returns an INCOHERENT mixture (audio + annotations).
Stems in INCOHERENT mixtures may come from different songs and are not temporally
aligned.
Parameters
----------
fg_folder : str
Path to the foreground source material for MUSDB18
bg_folder : str
Path to the background material for MUSDB18 (empty folder)
event_template: dict
Dictionary containing a template of probabilistic event parameters
seed : int or np.random.RandomState()
Seed for setting the Scaper object's random state. Different seeds will
generate different mixtures for the same source material and event template.
Returns
-------
mixture_audio : np.ndarray
Audio signal for the mixture
mixture_jams : np.ndarray
JAMS annotation for the mixture
annotation_list : list
Simple annotation in list format
stem_audio_list : list
List containing the audio signals of the stems that comprise the mixture
"""
# Create scaper object and seed random state
sc = scaper.Scaper(
duration=5.0,
fg_path=str(fg_folder),
bg_path=str(bg_folder),
random_state=seed
)
# Set sample rate, reference dB, and channels (mono)
sc.sr = 44100
sc.ref_db = -20
sc.n_channels = 1
# Copy the template so we can change it
event_parameters = event_template.copy()
# Iterate over stem types and add INCOHERENT events
labels = ['vocals', 'drums', 'bass', 'other']
for label in labels:
event_parameters['label'] = ('const', label)
sc.add_event(**event_parameters)
# Return the generated mixture audio + annotations
# while ensuring we prevent audio clipping
return sc.generate(fix_clipping=True)
def coherent(fg_folder, bg_folder, event_template, seed):
"""
This function takes the paths to the MUSDB18 source materials and a random seed,
and returns an COHERENT mixture (audio + annotations).
Stems in COHERENT mixtures come from the same song and are temporally aligned.
Parameters
----------
fg_folder : str
Path to the foreground source material for MUSDB18
bg_folder : str
Path to the background material for MUSDB18 (empty folder)
event_template: dict
Dictionary containing a template of probabilistic event parameters
seed : int or np.random.RandomState()
Seed for setting the Scaper object's random state. Different seeds will
generate different mixtures for the same source material and event template.
Returns
-------
mixture_audio : np.ndarray
Audio signal for the mixture
mixture_jams : np.ndarray
JAMS annotation for the mixture
annotation_list : list
Simple annotation in list format
stem_audio_list : list
List containing the audio signals of the stems that comprise the mixture
"""
# Create scaper object and seed random state
sc = scaper.Scaper(
duration=5.0,
fg_path=str(fg_folder),
bg_path=str(bg_folder),
random_state=seed
)
# Set sample rate, reference dB, and channels (mono)
sc.sr = 44100
sc.ref_db = -20
sc.n_channels = 1
# Copy the template so we can change it
event_parameters = event_template.copy()
# Instatiate the template once to randomly choose a song,
# a start time for the sources, a pitch shift and a time
# stretch. These values must remain COHERENT across all stems
sc.add_event(**event_parameters)
event = sc._instantiate_event(sc.fg_spec[0])
# Reset the Scaper object's the event specification
sc.reset_fg_event_spec()
# Replace the distributions for source time, pitch shift and
# time stretch with the constant values we just sampled, to
# ensure our added events (stems) are coherent.
event_parameters['source_time'] = ('const', event.source_time)
event_parameters['pitch_shift'] = ('const', event.pitch_shift)
event_parameters['time_stretch'] = ('const', event.time_stretch)
# Iterate over the four stems (vocals, drums, bass, other) and
# add COHERENT events.
labels = ['vocals', 'drums', 'bass', 'other']
for label in labels:
# Set the label to the stem we are adding
event_parameters['label'] = ('const', label)
# To ensure coherent source files (all from the same song), we leverage
# the fact that all the stems from the same song have the same filename.
# All we have to do is replace the stem file's parent folder name from "vocals"
# to the label we are adding in this iteration of the loop, which will give the
# correct path to the stem source file for this current label.
coherent_source_file = event.source_file.replace('vocals', label)
event_parameters['source_file'] = ('const', coherent_source_file)
# Add the event using the modified, COHERENT, event parameters
sc.add_event(**event_parameters)
# Generate and return the mixture audio, stem audio, and annotations
return sc.generate(fix_clipping=True)
Let’s generate and listen to some coherent and incoherent mixtures generated with our code!
# First double check our paths and template are correct:
print(fg_folder)
print(bg_folder)
print("")
print(template_event_parameters)
/home/runner/.nussl/ismir2020-tutorial/foreground
/home/runner/.nussl/ismir2020-tutorial/background
{'label': ('const', 'vocals'), 'source_file': ('choose', []), 'source_time': ('uniform', 0, 7), 'event_time': ('const', 0), 'event_duration': ('const', 5.0), 'snr': ('uniform', -5, 5), 'pitch_shift': ('uniform', -2, 2), 'time_stretch': ('uniform', 0.8, 1.2)}
Looks good, let’s generate:
# Generate 3 coherent mixtures
for seed in [1, 2, 3]:
mixture_audio, mixture_jam, annotation_list, stem_audio_list = coherent(
fg_folder,
bg_folder,
template_event_parameters,
seed)
display(Audio(data=mixture_audio.T, rate=sc.sr))
# Generate 3 incoherent mixtures
for seed in [1, 2, 3]:
mixture_audio, mixture_jam, annotation_list, stem_audio_list = incoherent(
fg_folder,
bg_folder,
template_event_parameters,
seed)
display(Audio(data=mixture_audio.T, rate=sc.sr))
Hurrah! We can generate radnomized, augmented, and annotated mixtures on the fly!
Plugging Scaper into nussl: generating training data on-the-fly¶
In the next Chapter we’ll learn how to use the nussl library to train source separation models. Before we can do this, the last thing we need to learn is how to plug Scaper output into nussl so we can generate training data on-the-fly.
To do this, we’ll wrap coherent() and incoherent() inside generate_mixture() which takes a nussl-loaded dataset, fg_folder, bg_folder, event_template, and an integer seed, and returns a mixture. Each time the function is called we flip a coin to determine if the mixture will be coherent or incoherent:
import numpy as np
def generate_mixture(dataset, fg_folder, bg_folder, event_template, seed):
# hide warnings
with warnings.catch_warnings():
warnings.filterwarnings('ignore')
# flip a coint to choose coherent or incoherent mixing
random_state = np.random.RandomState(seed)
# generate mixture
if random_state.rand() > .5:
data = coherent(fg_folder, bg_folder, event_template, seed)
else:
data = incoherent(fg_folder, bg_folder, event_template, seed)
# unpack the data
mixture_audio, mixture_jam, annotation_list, stem_audio_list = data
# convert mixture to nussl format
mix = dataset._load_audio_from_array(
audio_data=mixture_audio, sample_rate=dataset.sample_rate
)
# convert stems to nussl format
sources = {}
ann = mixture_jam.annotations.search(namespace='scaper')[0]
for obs, stem_audio in zip(ann.data, stem_audio_list):
key = obs.value['label']
sources[key] = dataset._load_audio_from_array(
audio_data=stem_audio, sample_rate=dataset.sample_rate
)
# store the mixture, stems and JAMS annotation in the format expected by nussl
output = {
'mix': mix,
'sources': sources,
'metadata': mixture_jam
}
return output
Finally, we’ll wrap our generate_mixture function in a nussl OnTheFly object which we’ll use as a data generator for nussl in the next Chapter:
# Convenience class so we don't need to enter the fg_folder, bg_folder, and template each time
class MixClosure:
def __init__(self, fg_folder, bg_folder, event_template):
self.fg_folder = fg_folder
self.bg_folder = bg_folder
self.event_template = event_template
def __call__(self, dataset, seed):
return generate_mixture(dataset, self.fg_folder, self.bg_folder, self.event_template, seed)
# Initialize our mixing function with our specific source material and event template
mix_func = MixClosure(fg_folder, bg_folder, template_event_parameters)
# Create a nussle OnTheFly data generator
on_the_fly = nussl.datasets.OnTheFly(
num_mixtures=1000,
mix_closure=mix_func
)
And that’s it! Infinite data generation, on the fly, ready to go into nussl!
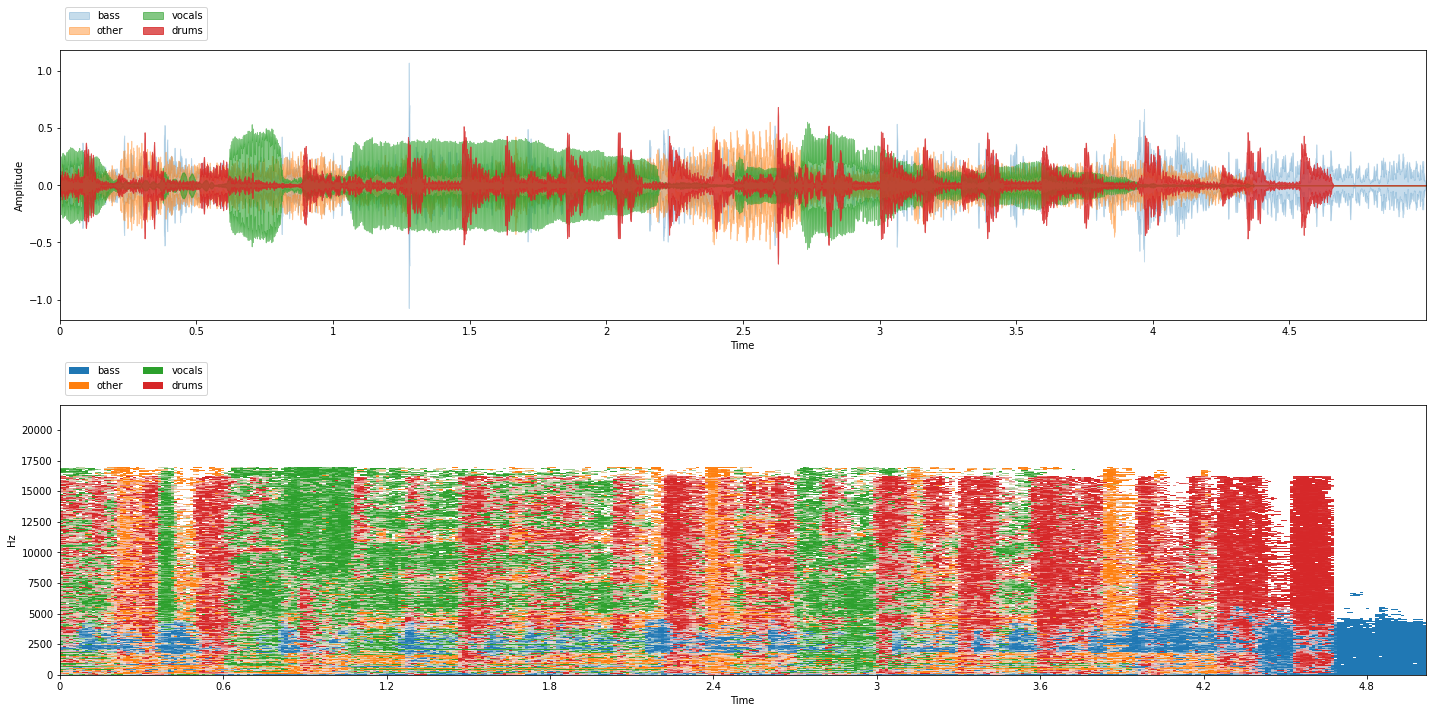
Let’s use our on_the_fly generator to visualize and listen to some generated mixtures:
from common import viz
for i in range(3):
item = on_the_fly[i]
mix = item['mix']
sources = item['sources']
viz.show_sources(sources)
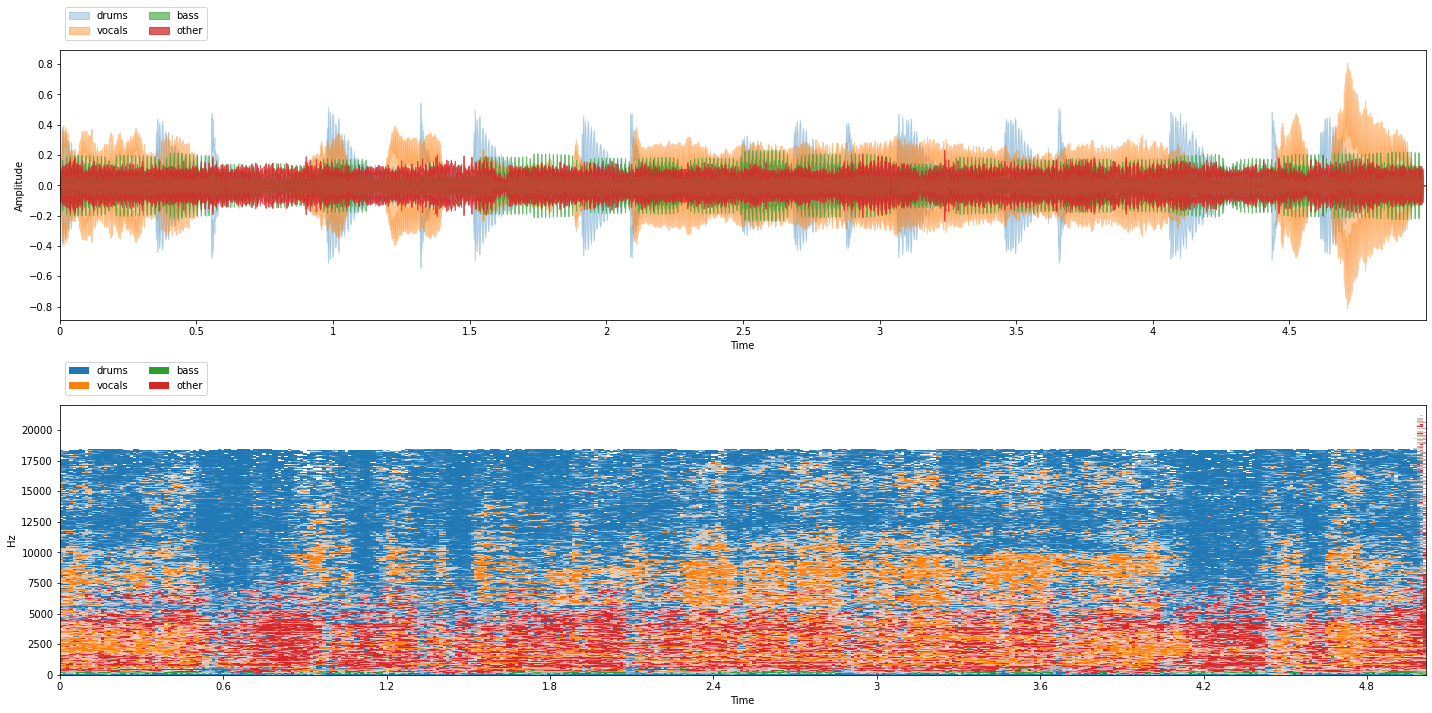
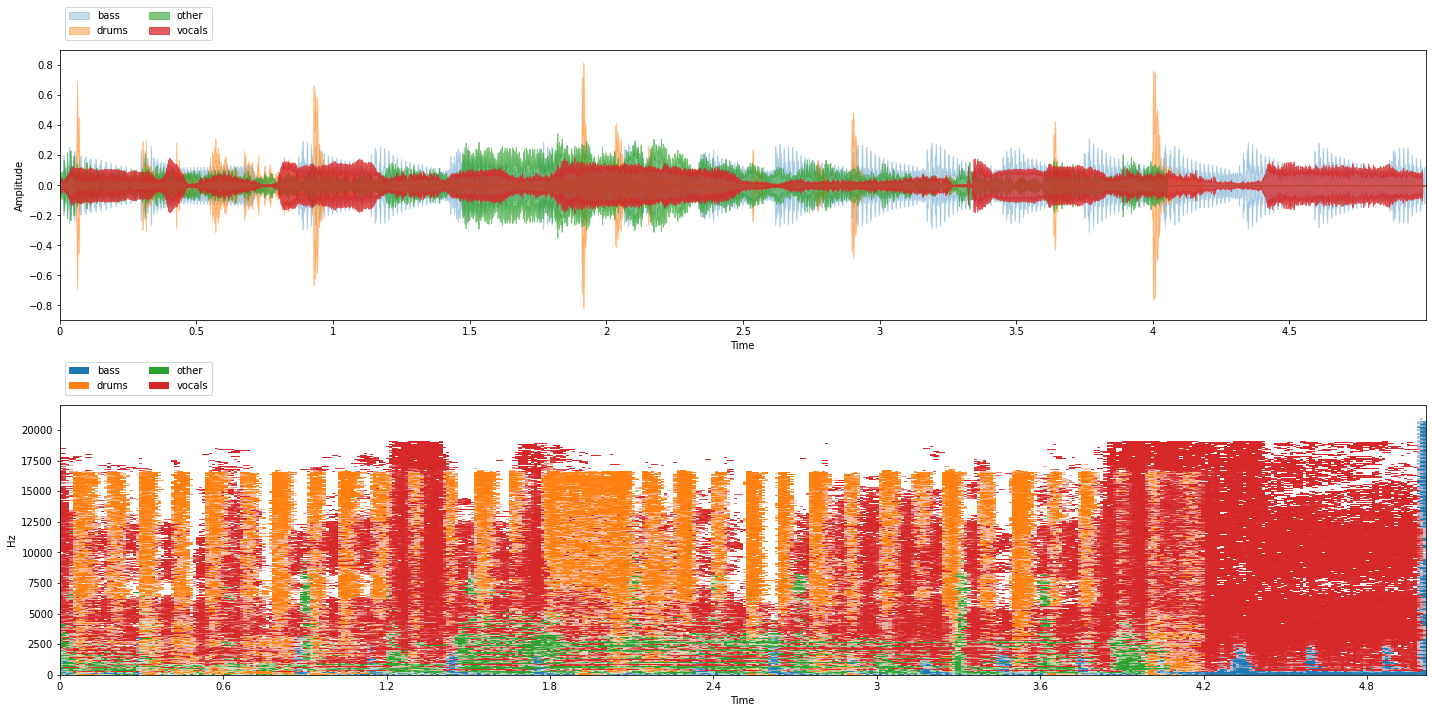
We’re all set! In the next Chapter we’ll see how to connect our on-the-fly mixture generator with nussl’s training and train source separation models!