Introduction¶
In this chapter we’ll cover the key aspects we need to know about data for source separation: what do data for source separation look like, relevant datasets and, importantly, how to programatically generate training data (mixtures) in a way that’s efficient, reproducible, and maximizes the performance we can squeeze out of our data.
Data for music source separation¶
At a high level, the inputs and outputs of a source separation model look like this:
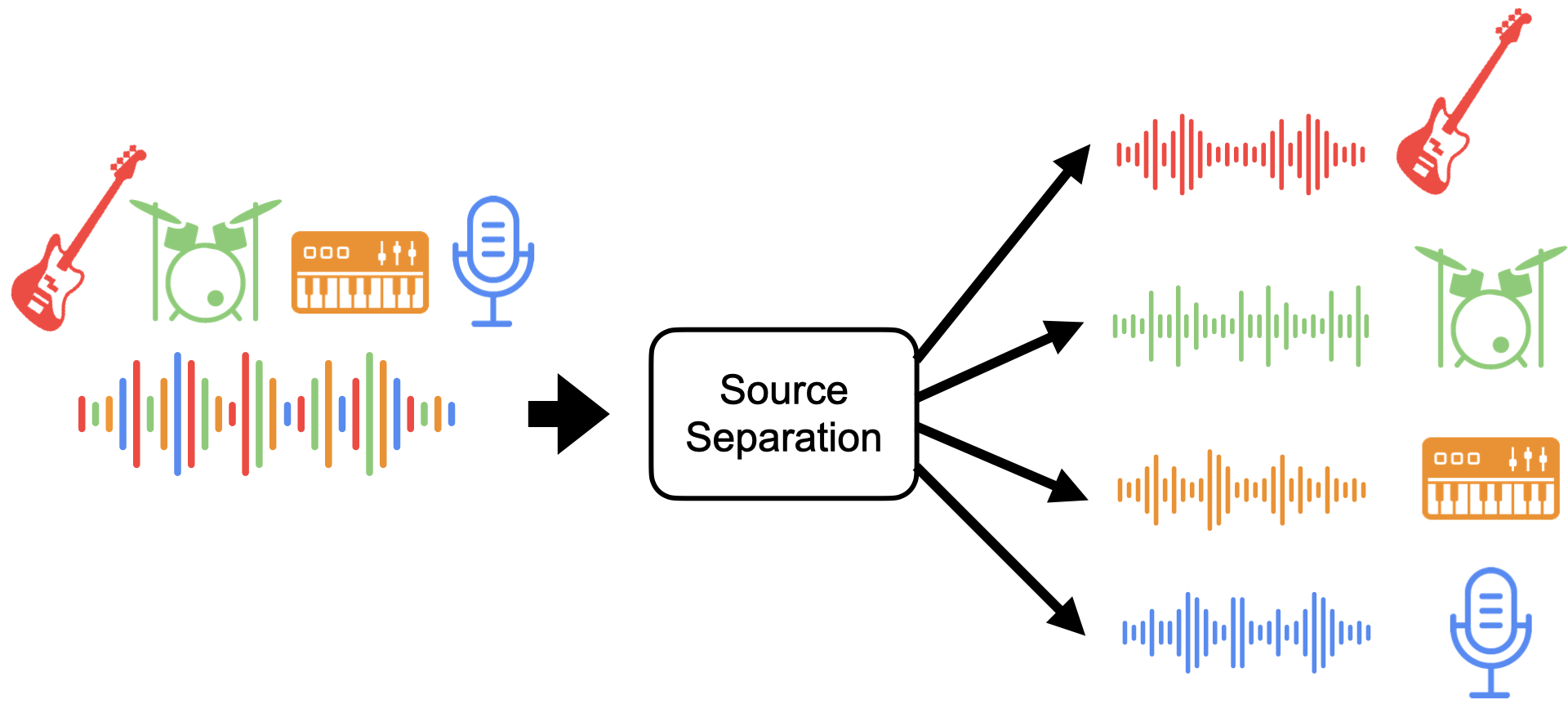
Fig. 43 Inputs and outputs of a source separation model.¶
For this tutorial, we will assume the inputs and outputs were created in the following way:
Each instrument or voice is recorded in isolation into a separate audio track, called a “stem”. The stem may be processed with effects such as compression, reverb, etc.
The mixture is obtained by summing the processed stems.
The model takes the mixture as input and outputs its estimate of each stem
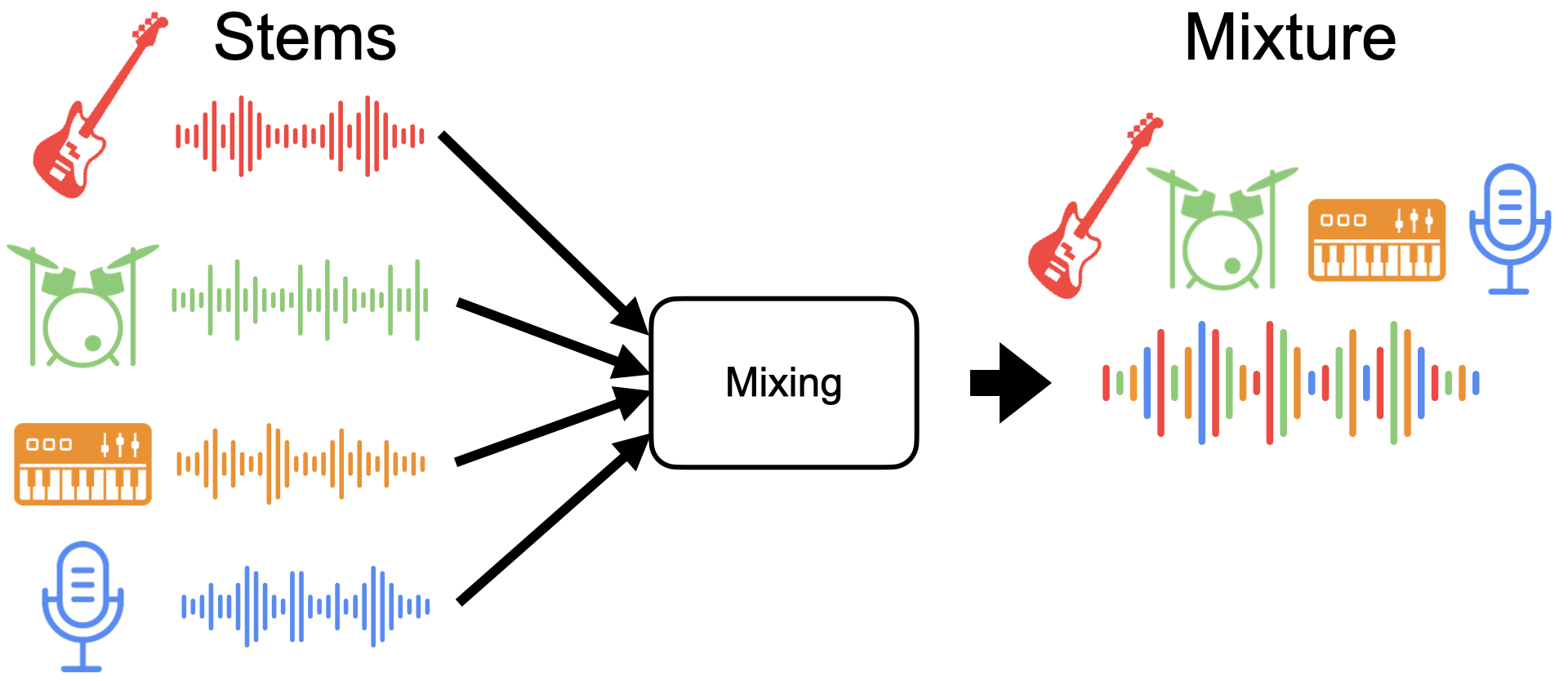
Fig. 44 Mixing stems to produce a mixture (mix).¶
Note
This is a simplified view of music creation. In practice, the mixture (musicians refer to this as the mix) typically goes through a mastering step which includes the application of multiple non-linear transformations to the mixture signal to produce the master, which is rarely a simple sum of the stems. Nonetheless, this simplified view (no mastering) allows us to train models that produce compelling results, as we shall see throughout this tutorial.
Since the master is not a linear sum of the stems, for training a source separation model we instead create our own mixture by summing the stems directly to create a linear mixture. When training a source separation model, we provide this mixture as input, the model outputs the estimated stems, and we compare these to the original stems that were used to create the mixture. The difference between the estimated stems and the original stems is used to update the model parameters during training:
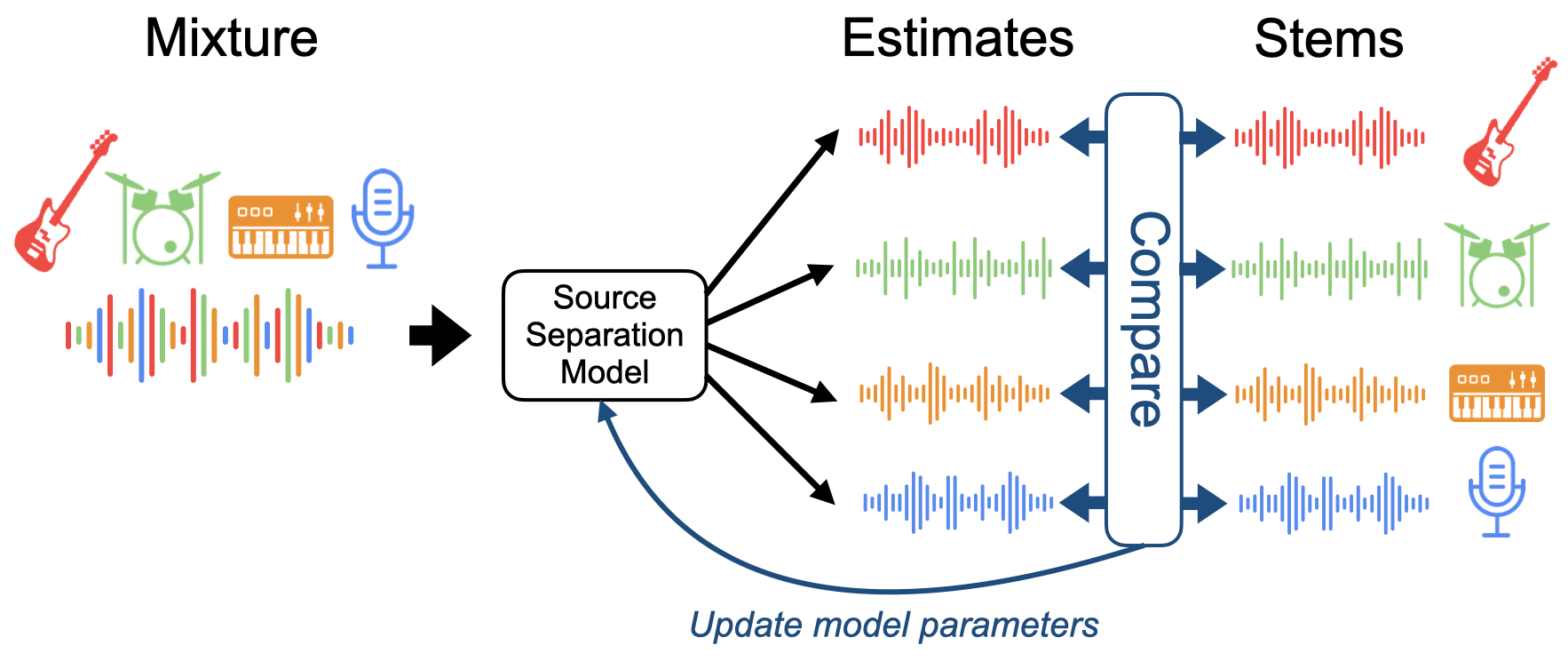
Fig. 45 High-level diagram of training a source separation model.¶
The difference between the estimated stems and original stems is also used to evaluate a trained source separation model, as we shall see later on.
Note
Our goal may not always be to separate all the stems. For example, we may want to train a model to only separate the vocals from the accompaniment (i.e., everything else) in a mixture. In this case we can think of the mixture as the sum of two stems: one containing the vocals and the other containing all other instruments. We can achieve this by mixing all but the vocal stems into an “accompaniment stem”, and train the model to separate the mixture into these two stems.
In summary, from a data standpoint, to train a music source separation model we need:
The isolated stems of all instruments/voices that comprise a music recording. This is commonly referred to as a “multi-track recording”, since each instrument is recorded on a separate track of a digital audio workstation (DAW).
The ability to programatically create mixtures from these stems for training and evaluation.
Data is a key component¶
Your model can only be as good as the data used to train it (the garbage in garbage out principle), and failing to use data (music) that is representative of the data you plan to apply your model to (sampling bias). It may be tempting to generate simple synthetic stems or make some multi-track recordings in the lab and use these to train a model. However, there is little to no chance that a model trained on such data will generalize to real-world music. Put simply, you need to train your model with data that is representative of the type of data you plan to apply your model to once it is trained.
Data for source separation is hard to obtain¶
Due to copyright, it is hard to obtain and share music recordings for machine learning purposes. It is even harder to obtain multi-track recordings that include the isolated stems, as these are rarely made available by artists. Fortunately, the research community has nonetheless been able to create and share multi-track datasets, as we shall see late. The size of these datasets is typically very small compared to other machine learning datasets. Luckily for us, we have tools to generate multiple, different mixtures from the same set of stems, helping us to maximize what our model can learn from a given set of stems.
Chapter outline¶
The remainder of this chapter is structured as follows:
In Datasets, we will provide an overview of existing datasets for training music source separation models.
In The MUSDB18 dataset, we will go into further detail about the dataset we will use in this tutorial.
In Data generation with Scaper, we will learn how to use the Scaper library to generate and augment mixtures on-the-fly for training and evaluation.
In Recap we will provide a brief recap (summary) of what we covered in this Chapter.